Regular Expressions Love Or Hate Them
Love or hate (like Marmite), there is no denying Regular Expressions are fantastic at extracting data from the web / html pages.
What is a Regular Expression ?
A regular expression is a super-powerful wildcard text matcher.
This super-powerful matcher can also be used to extract (capture) data at specific points in the wildcard.
So what is a wild card?
You many of used a wild card in Windows File Manager/ Explorer, if you want to find all photos or images in a jpeg format, you might type into the search
If you are familiar with SQL Server, TSQL has wild card syntax of ‘Like %’ to match to a certain piece of text in a database table.
SELECT Name
FROM Customer
WHERE Name LIKE ‘Ang%’
The SQL Server wildcard would return names such as:-
- Angela
- Angelica
- Angelina
- Angelo
- Angus
Regular Expressions are available in MS Word and NotePad++ giving users a much more powerful way to match to a certain wildcard (pattern).
So how do we use regular expressions to extract data from the web ?
Let’s suppose we want to get the title text from a bunch of web pages.
We have already downloaded the HTML source to disk, if we open the source in notepad at the top of the page you will have something like:-
We are interested in the text between the 2 title tags <title></title>.
Using the following Regular Expression, this is a nice easy match.
the captured text will be:-
But what if, on one of our web pages, the web developer has made a mistake and added an extra space at the end of the first tag. (show below with a ^)
Our regular expression will no longer match.
What can we do is, have a second pass looking for a tag with a single space.
<title\s>(.*?)</title>
But what if on one of our web pages, the developer has made a mistake and added an ANOTHER extra space at the end of the first TITLE tag.( show below with a ^^)
What we can do is, have a third pass looking for a tag with two spaces.
<title\s>(.*?)</title>
<title\s\s>(.*?)</title>
But what if on another web page a developer has added a 4th ,5th, 6th Space ?
The good news is, we can accommodate as many spaces using a regular expression like
So in one hit, job done (for now)
But what if on another web page a developer has added my mistake an attribute in the title tag
How do we accommodate this? And handle the possibility of extra space(s) ?
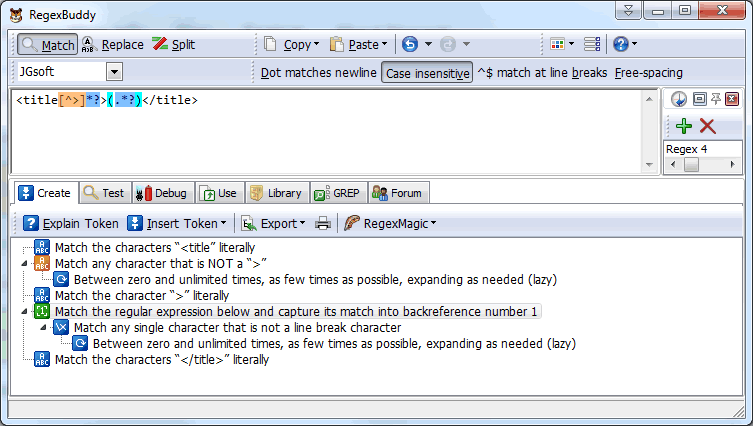
We well one is way using a single Regular Expression such as
This regular expression will :-
- Match the characters “<Title” literally.
- Match any character that is NOT a “>” until it matches a “>”
The above regular expression will accommodate all the spaces, attributes and anything else that might be in the title tag mistakenly.
Of course we could take this much further accommodating other wildcard patterns, but hopefully this demonstrates the usefulness of Regular Expressions when extracting data from web pages (HTML)
Regular Expressions, love or hate them, they are fantastic at extracting data from the web / html pages.