Scrape Tray Notification Tool Tips in CSharp
I wanted to know pro-grammatically via C# when my OneDrive was “Up To Date” or not.
I wondered if there was an API, and sure there is, see here for Live One Drive API.
I am not a One Drive API expert, but all the examples seemed to be specific for mobile applications and not for say Windows 7 or Windows 8.
I also have a drop box account, again if I wanted to know when its “Up To Date”, another API to investigate !
I then read on forums other people looking to do similar things with Drop Box and One Drive etc, and talk about scraping the data from the Tool Tip from the Tray Icon. Very Cunning !
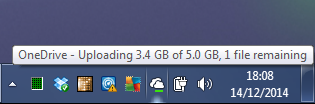
Mouse Over Tool Tip For One Drive
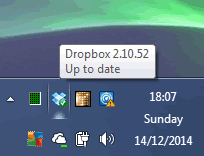
Mouse Over Tool Tip Drop Box
I saw a few posts about the ability to scrape from the Tool Tips, but not a complete demo example / solution.
After lots of digging around the Internet with some fantastic input from others, I managed to piece it all together and get this working.
Tested on : –
Windows 7
Windows 8.1
Windows Essentials Server 2012
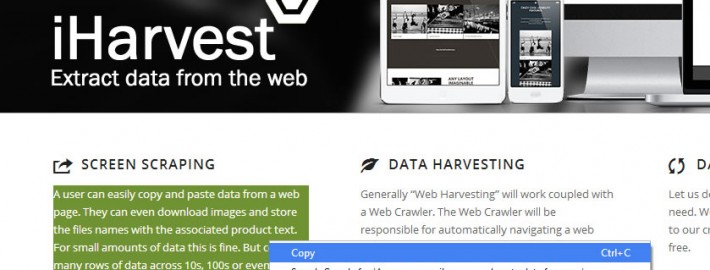
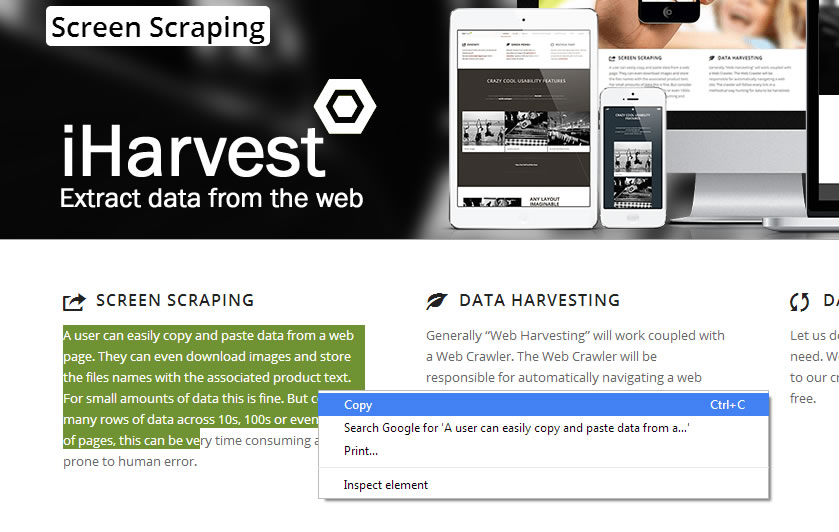
In the image below you can see we read from the Tool Tip that OneDrive was uploading a 5GB file, 2.9 GB was completed.
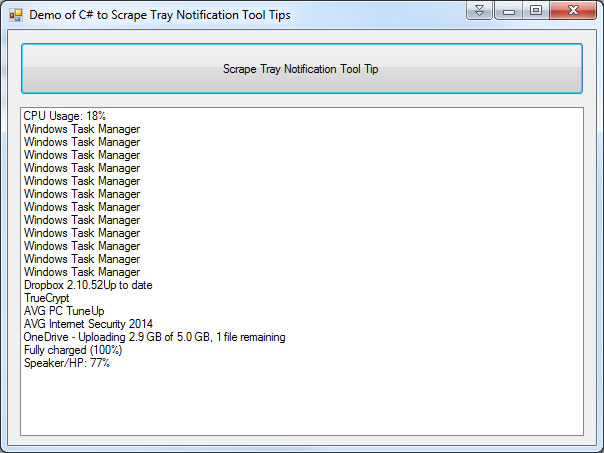
Scraped Tool Tips From the windows Notification / Tray Area.
Demo Project to Scrape Tray Notification Tool Tips in CSharp
Complete code below (and downloadable project).
Open Visual Studio and create a new Windows Application
On to your form drag over a Button and List Box for you have something like this
Scrape Tray Notification Tool Tips
Scrape Tray Notification Tool Tips
Now double click your button and add the following code:-
{
listBox1.Items.Clear ();List<string> myList = ScrapeTrayNotificationToolTips.GetToolTipText();foreach (string myString in myList)
{
listBox1.Items.Add(myString);}
}
Next add an new class to your project called say
ScrapeTrayNotificationToolTips.cs
Add these name spaces :-
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Runtime.InteropServices;
using System.Diagnostics;
using Microsoft.VisualBasic;
Paste in the code below :-
public static class ScrapeTrayNotificationToolTips
{
//Scrape Tray Notification Tool Tips
public static List<string> GetToolTipText ()
{
List<string> retVal = new List<string>();
IntPtr _ToolbarWindowHandle = GetSystemTrayHandle();
UInt32 count = User32.SendMessage(_ToolbarWindowHandle, TB.BUTTONCOUNT, 0, 0);
for (int i = 0; i < count; i++)
{
TBBUTTON tbButton = new TBBUTTON();
string text = String.Empty;
IntPtr ipWindowHandle = IntPtr.Zero;
bool b = GetTBButton(_ToolbarWindowHandle, i, ref tbButton, ref text, ref ipWindowHandle);
retVal.Add(text);
}
return retVal;
}
private static IntPtr GetSystemTrayHandle()
{
IntPtr hWndTray = User32.FindWindow(“Shell_TrayWnd”, null);
if (hWndTray != IntPtr.Zero)
{
hWndTray = User32.FindWindowEx(hWndTray, IntPtr.Zero, “TrayNotifyWnd”, null);
if (hWndTray != IntPtr.Zero)
{
hWndTray = User32.FindWindowEx(hWndTray, IntPtr.Zero, “SysPager”, null);
if (hWndTray != IntPtr.Zero)
{
hWndTray = User32.FindWindowEx(hWndTray, IntPtr.Zero, “ToolbarWindow32″, null);
return hWndTray;
}
}
}
return IntPtr.Zero;
}
internal static unsafe bool GetTBButton(IntPtr hToolbar, int i, ref TBBUTTON tbButton, ref string text, ref IntPtr ipWindowHandle)
{
// One page
const int BUFFER_SIZE = 0x1000;
byte[] localBuffer = new byte[BUFFER_SIZE];
UInt32 processId = 0;
UInt32 threadId = User32.GetWindowThreadProcessId(hToolbar, out processId);
IntPtr hProcess = Kernel32.OpenProcess(ProcessRights.ALL_ACCESS, false, processId);
if (hProcess == IntPtr.Zero) { Debug.Assert(false); return false; }
IntPtr ipRemoteBuffer = Kernel32.VirtualAllocEx(
hProcess,
IntPtr.Zero,
new UIntPtr(BUFFER_SIZE),
MemAllocationType.COMMIT,
MemoryProtection.PAGE_READWRITE);
if (ipRemoteBuffer == IntPtr.Zero) { Debug.Assert(false); return false; }
// TBButton
fixed (TBBUTTON* pTBButton = &tbButton)
{
IntPtr ipTBButton = new IntPtr(pTBButton);
int b = (int)User32.SendMessage(hToolbar, TB.GETBUTTON, (IntPtr)i, ipRemoteBuffer);
if (b == 0) { Debug.Assert(false); return false; }
// this is fixed
Int32 dwBytesRead = 0;
IntPtr ipBytesRead = new IntPtr(&dwBytesRead);
bool b2 = Kernel32.ReadProcessMemory(
hProcess,
ipRemoteBuffer,
ipTBButton,
new UIntPtr((uint)sizeof(TBBUTTON)),
ipBytesRead);
if (!b2) { Debug.Assert(false); return false; }
}
// button text
fixed (byte* pLocalBuffer = localBuffer)
{
IntPtr ipLocalBuffer = new IntPtr(pLocalBuffer);
int chars = (int)User32.SendMessage(hToolbar, TB.GETBUTTONTEXTW, (IntPtr)tbButton.idCommand, ipRemoteBuffer);
if (chars == -1) { Debug.Assert(false); return false; }
// this is fixed
Int32 dwBytesRead = 0;
IntPtr ipBytesRead = new IntPtr(&dwBytesRead);
bool b4 = Kernel32.ReadProcessMemory(
hProcess,
ipRemoteBuffer,
ipLocalBuffer,
new UIntPtr(BUFFER_SIZE),
ipBytesRead);
if (!b4) { Debug.Assert(false); return false; }
text = Marshal.PtrToStringUni(ipLocalBuffer, chars);
if (text == ” “) text = String.Empty;
}
Kernel32.VirtualFreeEx(
hProcess,
ipRemoteBuffer,
UIntPtr.Zero,
MemAllocationType.RELEASE);
Kernel32.CloseHandle(hProcess);
return true;
}
}
internal class MemAllocationType
{
public const UInt32 COMMIT = 0x1000;
public const UInt32 RESERVE = 0x2000;
public const UInt32 DECOMMIT = 0x4000;
public const UInt32 RELEASE = 0x8000;
public const UInt32 FREE = 0x10000;
public const UInt32 PRIVATE = 0x20000;
public const UInt32 MAPPED = 0x40000;
public const UInt32 RESET = 0x80000;
public const UInt32 TOP_DOWN = 0x100000;
public const UInt32 WRITE_WATCH = 0x200000;
public const UInt32 PHYSICAL = 0x400000;
public const UInt32 LARGE_PAGES = 0x20000000;
public const UInt32 FOURMB_PAGES = 0x80000000;
}
internal class MemoryProtection
{
public const UInt32 PAGE_NOACCESS = 0x01;
public const UInt32 PAGE_READONLY = 0x02;
public const UInt32 PAGE_READWRITE = 0x04;
public const UInt32 PAGE_WRITECOPY = 0x08;
public const UInt32 PAGE_EXECUTE = 0x10;
public const UInt32 PAGE_EXECUTE_READ = 0x20;
public const UInt32 PAGE_EXECUTE_READWRITE = 0x40;
public const UInt32 PAGE_EXECUTE_WRITECOPY = 0x80;
public const UInt32 PAGE_GUARD = 0x100;
public const UInt32 PAGE_NOCACHE = 0x200;
public const UInt32 PAGE_WRITECOMBINE = 0x400;
}
internal class ProcessRights
{
public const UInt32 TERMINATE = 0x0001;
public const UInt32 CREATE_THREAD = 0x0002;
public const UInt32 SET_SESSIONID = 0x0004;
public const UInt32 VM_OPERATION = 0x0008;
public const UInt32 VM_READ = 0x0010;
public const UInt32 VM_WRITE = 0x0020;
public const UInt32 DUP_HANDLE = 0x0040;
public const UInt32 CREATE_PROCESS = 0x0080;
public const UInt32 SET_QUOTA = 0x0100;
public const UInt32 SET_INFORMATION = 0x0200;
public const UInt32 QUERY_INFORMATION = 0x0400;
public const UInt32 SUSPEND_RESUME = 0x0800;
private const UInt32 STANDARD_RIGHTS_REQUIRED = 0x000F0000;
private const UInt32 SYNCHRONIZE = 0x00100000;
public const uint ALL_ACCESS = STANDARD_RIGHTS_REQUIRED | SYNCHRONIZE | 0xFFF;
}
//many thanks to Paul Accisano for finding out the nitty grtty on this struct.
//http://stackoverflow.com/questions/5495981/how-do-i-define-the-tbbutton-struct-in-c/5518286
//x86 and x64 compatible
[StructLayout(LayoutKind.Sequential)]
internal struct TBBUTTON
{
public int iBitmap;
public int idCommand;
[StructLayout(LayoutKind.Explicit)]
private struct TBBUTTON_U
{
[FieldOffset(0)]
public byte fsState;
[FieldOffset(1)]
public byte fsStyle;
[FieldOffset(0)]
private IntPtr bReserved;
}
private TBBUTTON_U union;
public byte fsState { get { return union.fsState; } set { union.fsState = value; } }
public byte fsStyle { get { return union.fsStyle; } set { union.fsStyle = value; } }
public IntPtr dwData;
public IntPtr iString;
}
internal class WM
{
public const uint CLOSE = 0x0010;
public const uint GETICON = 0x007F;
public const uint KEYDOWN = 0x0100;
public const uint COMMAND = 0x0111;
public const uint USER = 0x0400; // 0x0400 – 0x7FFF
public const uint APP = 0x8000; // 0x8000 – 0xBFFF
}
internal class TB
{
public const uint GETBUTTON = WM.USER + 23;
public const uint BUTTONCOUNT = WM.USER + 24;
public const uint CUSTOMIZE = WM.USER + 27;
public const uint GETBUTTONTEXTA = WM.USER + 45;
public const uint GETBUTTONTEXTW = WM.USER + 75;
public const uint WM_LBUTTONDBLCLK = 0x0203;
public const uint PRESSBUTTON = (WM.USER + 3);
public const uint HIDEBUTTON = (WM.USER + 4);
public const uint GETITEMRECT = (WM.USER + 29);
public const uint STATE_HIDDEN = 0x08;
}
internal static class Kernel32
{
[DllImport(“kernel32.dll”, CharSet = CharSet.Auto, SetLastError = true)]
public static extern IntPtr GetModuleHandle(string lpModuleName);
[DllImport(“kernel32.dll”)]
public static extern IntPtr OpenProcess(UInt32 dwDesiredAccess, Int32 bInheritHandle, UInt32 dwProcessId);
[DllImport(“Kernel32.dll”, SetLastError = true)]
public static extern IntPtr OpenProcess(uint dwDesiredAccess, bool bInheritHandle, uint dwProcessId);
[DllImport(“kernel32.dll”)]
[return: MarshalAs(UnmanagedType.Bool)]
public static extern bool CloseHandle(IntPtr hObject);
[DllImport(“kernel32.dll”, SetLastError = true, CharSet = CharSet.Auto)]
public static extern IntPtr VirtualAllocEx(IntPtr hProcess, IntPtr lpAddress, Int32 dwSize, uint flAllocationType, uint flProtect);
[DllImport(“kernel32.dll”, SetLastError = true)]
public static extern IntPtr VirtualAllocEx(
IntPtr hProcess,
IntPtr lpAddress,
UIntPtr dwSize,
uint flAllocationType,
uint flProtect);
[DllImport(“kernel32.dll”)]
public static extern bool ReadProcessMemory(
IntPtr hProcess,
IntPtr lpBaseAddress,
IntPtr lpBuffer,
UIntPtr nSize,
IntPtr lpNumberOfBytesRead);
[DllImport(“kernel32.dll”, SetLastError = true, CharSet = CharSet.Auto)]
public static extern Int32 ReadProcessMemory(IntPtr hProcess, IntPtr lpBaseAddress, [In, Out] byte[] lpBuffer, Int32 nSize, out Int32 lpNumberOfBytesRead);
[DllImport(“kernel32.dll”)]
public static extern bool VirtualFreeEx(
IntPtr hProcess,
IntPtr lpAddress,
UIntPtr dwSize,
UInt32 dwFreeType);
}
internal static class User32
{
[DllImport(“user32.dll”, SetLastError = true)]
public static extern IntPtr FindWindowEx(IntPtr hWndParent, IntPtr hWndChildAfter, string lpClassName, string lpWindowName);
[DllImport(“user32.dll”, SetLastError = true)]
public static extern IntPtr FindWindow(string lpClassName, string lpWindowName);
[DllImport(“user32.dll”)]
public static extern IntPtr SendMessage(IntPtr hWnd, UInt32 msg, IntPtr wParam, IntPtr lParam);
[DllImport(“user32.dll”)]
public static extern UInt32 SendMessage(IntPtr hWnd, UInt32 msg, UInt32 wParam, UInt32 lParam);
[DllImport(“user32.dll”)]
public static extern uint GetWindowThreadProcessId(IntPtr hWnd, out uint lpdwProcessId);
}
Huge thanks to these 2 url’s :-
https://github.com/Mpdreamz/tabalt
http://stackoverflow.com/questions/6366505/get-tooltip-text-from-icon-in-system-tray
Other Reference Sites :-
http://www.codeproject.com/Articles/10807/Shell-Tray-Info-Arrange-your-system-tray-icons
http://stackoverflow.com/questions/26724848/how-to-access-onedrive-s-notification-status-in-c-sharp